# React 18 新特性
# 0、react 的迭代过程
- v16: Async Mode (异步模式),变为异步、可中断的;
- v17: Concurrent Mode (并发模式),让 commit 在用户的感知上是并发的;
- v18: Concurrent Render (并发更新),Concurrent Mode中包含 breaking change,比如很多库不兼容(mobx等),所以v18 提出了 Concurrent Render ,减少了开发者的迁移成本。
React 中 Fiber 树的更新流程分为两个阶段 render 阶段和 commit 阶段。组件的 render 函数执行时称为 render(本次更新需要做哪些变更),纯 js 计算;而将 render 的结果渲染到页面的过程称为 commit (变更到真实的宿主环境中,在浏览器中就是操作DOM)。
在 Sync 模式下,render 阶段是一次性执行完成;而在 Concurrent 模式下 render 阶段可以被拆解,每个时间片内执行一部分,直到执行完毕。由于 commit 阶段有 DOM 的更新,不可能让 DOM 更新到一半中断,必须一次性执行完毕
并发渲染机制concurrent rendering)的目的:根据用户的设备性能和网速对渲染过程进行适当的调整, 保证 React 应用在长时间的渲染过程中依旧保持可交互性,避免页面出现卡顿或无响应的情况,从而提升用户体验。 v18 正式引入了的并发渲染机制,并基于此给我们带来了很多新特性。这些新特性都是可选的并发功能,使用了这些新特性的组件并能触发并发渲染,并且与其整个子树都将自动开启 strictMode。
# 1、放弃IE 11
React 18 已经放弃了对 ie11 的支持,将于 2022年6月15日 停止支持 ie,如需兼容,需要回退到 React 17 版本。
WARNING
React 18 中引入的新特性是使用现代浏览器的特性构建的,在IE中无法充分polyfill,比如micro-tasks
# 2、createRoot 相关更改
# 2.1 createRoot
React 18 提供了两个根 API,我们称之为 Legacy Root API(ReactDOM.render) 和 New Root API(createRoot)。
- Legacy root API: 即 ReactDOM.render。这将创建一个以“遗留”模式运行的 root,其工作方式与 React 17 完全相同。使用此 API 会有一个警告,表明它已被弃用并切换到 New Root API。
- New Root API: 即 createRoot。 这将创建一个在 React 18 中运行的 root,它添加了 React 18 的所有改进并允许使用并发功能。
import * as ReactDOM from 'react-dom'
import App from './App'
const root = document.getElementById('app')
// v18 之前的方法
ReactDOM.render(<App/>,root)
2
3
4
5
6
import * as ReactDOM from 'react-dom/client'
import App from './App'
const root = ReactDOM.createRoot(document.getElementById('app'))
// v18 的新方法
root.render(<App/>)
2
3
4
5
6
TIP
想要使用 v18 中其他新特性 API, 前提是要使用新的 Root API 来创建根节点。
在 TypeScript, createRoot 中参数 container 可接收 HTMLElement ,但不能为空。使用要么断言,要么加判断吧~
# 2.2、组件卸载
同时,在卸载组件时,我们也需要将 unmountComponentAtNode 升级为 root.unmount:
// React 17
ReactDOM.unmountComponentAtNode(root);
// React 18
root.unmount();
2
3
4
5
TIP
我们如果在 React 18 中使用旧的 render api,在项目启动后,你将会在控制台中看到一个警告:

这表示你可以将项目直接升级到 React 18 版本,而不会直接造成 break change。如果你需要保持着 React 17 版本的特性的话,那么你可以无视这个报错,因为它在整个 18 版本中都是兼容的。
# 2.3、render 的回调
React 18 还从 render 方法中删除了回调函数,因为当使用Suspense时,它通常不会有预期的结果。
在新版本中,如果需要在 render 方法中使用回调函数,我们可以在组件中通过 useEffect 实现:
// React 17
const root = document.getElementById('root')!;
ReactDOM.render(<App />, root, () => {
console.log('渲染完成');
});
// React 18
const AppWithCallback: React.FC = () => {
useEffect(() => {
console.log('渲染完成');
}, []);
return <App />;
};
const root = document.getElementById('root')!;
ReactDOM.createRoot(root).render(<AppWithCallback />);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 2.4、TypeScript 下的children
还需要更新 TypeScript 类型定义,如果你的项目使用了 TypeScript,最值得注意的变化是,现在在定义props类型时,如果需要获取子组件children,那么你需要显式的定义它,例如这样:
// React 17
interface MyButtonProps {
color: string;
}
const MyButton: React.FC<MyButtonProps> = ({ children }) => {
// 在 React 17 的 FC 中,默认携带了 children 属性
return <div>{children}</div>;
};
export default MyButton;
// React 18
interface MyButtonProps {
color: string;
children?: React.ReactNode;
}
const MyButton: React.FC<MyButtonProps> = ({ children }) => {
// 在 React 18 的 FC 中,不存在 children 属性,需要手动申明
return <div>{children}</div>;
};
export default MyButton;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 3、服务端渲染(hydrateRoot)
如果的应用使用带注水的服务端渲染,请升级 hydrate 到 hydrateRoot;
// React 17
import ReactDOM from 'react-dom';
const root = document.getElementById('root');
ReactDOM.hydrate(<App />, root);
// React 18
import ReactDOM from 'react-dom/client';
const root = document.getElementById('root')!;
ReactDOM.hydrateRoot(root, <App />);
2
3
4
5
6
7
8
9
- renderToNodeStream => renderToPipeableStream
- 新增 renderToReadableStream 以支持 Deno
- 继续使用 renderToString (对 Suspense 支持有限)
- 继续使用 renderToStaticMarkup (对 Suspense 支持有限)
Suspense 的作用: 划分页面中需要并发渲染的部分。
hydration[水化]:ssr 时服务器输出的是字符串(html),客户端(一般是浏览器)根据这些字符串并结合加载的 JavaScript 来完成 React 的初始化工作这一阶段为水化。
React v18 之前的 SSR, 客户端必须一次性的等待 HTML 数据加载到服务器上并且等待所有 JavaScript 加载完毕之后再开始 hydration, 等待所有组件 hydration 后,才能进行交互。即整个过程需要完成从获取数据(服务器)→ 渲染到 HTML(服务器)→ 加载代码(客户端)→ 水合物(客户端)这一套流程。这样的 SSR 并不能使我们的完全可交互变快,只是提高了用户的感知静态页面内容的速度。
React v18 在 SSR 下支持了Suspense,最大的区别是什么呢?
- 1、服务器不需要等待被Suspense 包裹组件是否加载到完毕,即可发送 HTML,而代替 suspense 包裹的组件是fallback中的内容,一般是一个占位符(spinner),以最小内联
<script>标签标记此 HTML 的位置。等待服务器上组件的数据准备好后,React 再将剩余的 HTML发送到同一个流中。 - 2、hydration 的过程是逐步的,不需要等待所有的 js 加载完毕再开始 hydration,避免了页面的卡顿。
- 3、React 会提前监听页面上交互事件(如鼠标的点击),对发生交互的区域优先级进行 hydration
# 4、Suspense不再需要fallback来捕获
在 React 18 的 Suspense 组件中,官方对 空的fallback 属性的处理方式做了改变:不再跳过 缺失值 或 值为null 的 fallback 的 Suspense 边界。相反,会捕获边界并且向外层查找,如果查找不到,将会把 fallback 呈现为 null。
更新前:
以前,如果你的 Suspense 组件没有提供 fallback 属性,React 就会悄悄跳过它,继续向上搜索下一个边界
// React 17
const App = () => {
return (
<Suspense fallback={<Loading />}> // <--- 这个边界被使用,显示 Loading 组件
<Suspense> // <--- 这个边界被跳过,没有 fallback 属性
<Page />
</Suspense>
</Suspense>
);
};
export default App;
2
3
4
5
6
7
8
9
10
11
12
React 工作组发现这可能会导致混乱、难以调试的情况发生。例如,你正在debug一个问题,并且在没有 fallback 属性的 Suspense 组件中抛出一个边界来测试一个问题,它可能会带来一些意想不到的结果,并且 不会警告 说它 没有fallback 属性。
更新后:
现在,React将使用当前组件的 Suspense 作为边界,即使当前组件的 Suspense 的值为 null 或 undefined
// React 18
const App = () => {
return (
<Suspense fallback={<Loading />}> // <--- 不使用
<Suspense> // <--- 这个边界被使用,将 fallback 渲染为 null
<Page />
</Suspense>
</Suspense>
);
};
export default App;
2
3
4
5
6
7
8
9
10
11
12
这个更新意味着我们不再跨越边界组件。相反,我们将在边界处捕获并呈现 fallback,就像你提供了一个返回值为 null 的组件一样。这意味着被挂起的 Suspense 组件将按照预期结果去执行,如果忘记提供 fallback 属性,也不会有什么问题。
# 5、批量更新
这是 React 此次版本中最大的破坏性更新,并且无法向下兼容。
React 中的批处理简单来说就是将多个状态更新合并为一次重新渲染,以获得更好的性能,在 React 18 之前,React 只能在组件的生命周期函数或者合成事件函数中进行批处理。默认情况下,Promise、setTimeout 以及原生事件中是不会对其进行批处理的。如果需要保持批处理,则可以用 unstable_batchedUpdates 来实现,但它不是一个正式的 API。
function handleClick() {
setCount(1);
setFlag(true);
// 批处理:会合并为一次 render
}
function handleClick() {
Promise.resolve().then(() => {
setCount(2);
});
setFlag(false);
// 同步模式:会执行两次 render
// 并且在 setCount 后,在 setFlag 之前能通过 Ref 获取到最新的 count 值
}
2
3
4
5
6
7
8
9
10
11
12
13
14
在 React 18 上面的第二个例子只会有一次 render,因为所有的更新都将自动批处理。这样无疑是很好的提高了应用的整体性能。
不过以下例子会在 React 18 中执行两次 render:
async function handleClick() {
await setCount(2);
setFlag(false);
// React 18:会执行两次 render
}
2
3
4
5
# 6、退出批量更新(flushSync)
如果我想在 React 18 退出批处理该怎么做呢?官方提供了一个 API flushSync。
它接收一个函数作为参数,并且允许有返回值。
flushSync<R>(fn: () => R): R
function handleClick() {
flushSync(() => {
setCount(3);
});
// 会在 setCount 并 render 之后再执行 setFlag
setFlag(true);
}
2
3
4
5
6
7
8
9
WARNING
flushSync 会以函数为作用域,函数内部的多个 setState 仍然为批量更新,这样可以精准控制哪些不需要的批量更新:
function handleClick() {
flushSync(() => {
setCount(3);
setFlag(true);
});
// setCount 和 setFlag 为批量更新,结束后
setLoading(false);
// 此方法会触发两次 render
}
2
3
4
5
6
7
8
9
这种方式会比 React 17 及以前的方式更优雅的颗粒度控制 rerender。
flushSync 再某些场景中非常有用,比如在点击一个表单中点击保存按钮,并触发子表单关闭,并同步到全局 state,状态更新后再调用保存方法:
// 子表单
export default function ChildForm({ storeTo }) {
const [form] = Form.useForm();
// 当前组件卸载时将子表单的值同步到全局
// 若要触发父组件同步 setState,必须使用 useLayoutEffect
useLayoutEffect(() => {
return () => {
storeTo(form.getFieldsValue());
};
}, []);
return (
<Form form={form}>
<Form.Item name="email">
<Input />
</Form.Item>
</Form>
);
}
// 外部容器
<div
onClick={() => {
// 触发子表单卸载关闭
flushSync(() => setVisible(false));
// 子表单值更新到全局后,触发保存方法,可以保证 onSave 获取到最新填写的表单值
onSave();
}}
>
保存
</div>
<div>{visible && <ChildForm storeTo={updateState} />}</div>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
不过 unstable_batchedUpdates 在 React 18 中将继续保留整个版本,因为许多开源库用了它
# 7、卸载组件时的更新状态警告
我们在开发时,偶尔会遇到以下错误:
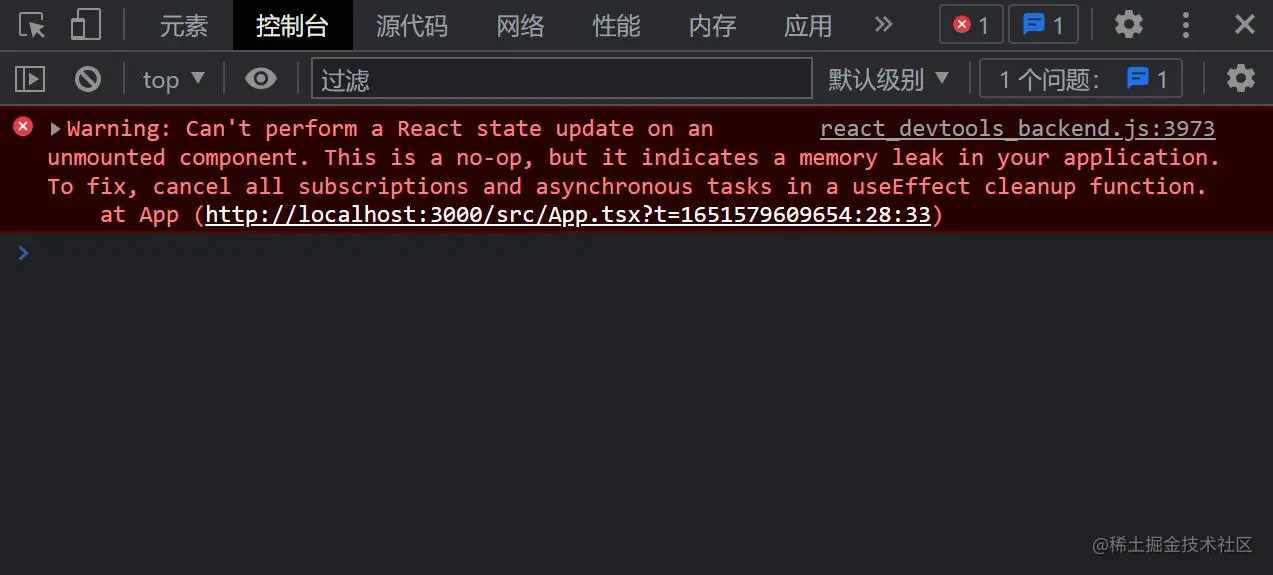
这个错误表示:无法对未挂载(已卸载)的组件执行状态更新。这是一个无效操作,并且表明我们的代码中存在内存泄漏。
这个错误的初衷,原本旨在针对一些特殊场景,譬如 你在useEffect里面设置了定时器,或者订阅了某个事件,从而在组件内部产生了副作用,而且忘记return一个函数清除副作用,则会发生内存泄漏…… 之类的场景。
但是在实际开发中,更多的场景是,我们在 useEffect 里面发送了一个异步请求,在异步函数还没有被 resolve 或者被 reject 的时候,我们就卸载了组件。 在这种场景中,警告同样会触发。但是,在这种情况下,组件内部并没有内存泄漏,因为这个异步函数已经被垃圾回收了,此时,警告具有误导性。
综上所述原因,在 React 18 中,官方删除了这个报错。
# 8、React 组件的返回值
在 React 17 中,如果你需要返回一个空组件,React只允许返回null。如果你显式的返回了 undefined,控制台则会在运行时抛出一个错误。
在 React 18 中,不再检查因返回 undefined 而导致崩溃。既能返回 null,也能返回 undefined(但是 React 18 的dts文件还是会检查,只允许返回 null,你可以忽略这个类型错误)
# 9、Strict Mode
当你使用严格模式时,React 会对每个组件进行两次渲染,以便你观察一些意想不到的结果。在 React 17 中,取消了其中一次渲染的控制台日志,以便让日志更容易阅读。
为了解决社区对这个问题的困惑,在 React 18 中,官方取消了这个限制。如果你安装了React DevTools > 4.18.0,第二次渲染的日志信息将显示为灰色,以柔和的方式显式在控制台。

TIP
- 1、这是 React18 才新增的特性。
- 2、仅在
开发模式("development")下,且使用了严格模式("Strict Mode")下会触发。生产环境("production")模式下和原来一样,仅执行一次。 - 3、之所以执行两次,是为了模拟立即卸载组件和重新挂载组件。
- 为了帮助开发者提前发现重复挂载造成的 Bug 的代码。
- 同时,也是为了以后 React的新功能做铺垫。未来会给 React 增加一个特性,允许 React 在保留状态的同时,能够做到仅仅对UI部分的添加和删除。 让开发者能够提前习惯和适应,做到组件的卸载和重新挂载之后, 重复执行 useEffect的时候不会影响应用正常运行。
# 10、新 API
# 10.1、useSyncExternalStore
useSyncExternalStore 是一个新的api,经历了一次修改,由 useMutableSource 改变而来,主要用来解决外部数据撕裂问题。
useSyncExternalStore 能够通过强制同步更新数据让 React 组件在 CM 下安全地有效地读取外接数据源。 在 Concurrent Mode 下,React 一次渲染会分片执行(以 fiber 为单位),中间可能穿插优先级更高的更新。假如在高优先级的更新中改变了公共数据(比如 redux 中的数据),那之前低优先的渲染必须要重新开始执行,否则就会出现前后状态不一致的情况。
useSyncExternalStore 一般是三方状态管理库使用,我们在日常业务中不需要关注。因为 React 自身的 useState 已经原生的解决的并发特性下的 tear(撕裂)问题。useSyncExternalStore 主要对于框架开发者,比如 redux,它在控制状态时可能并非直接使用的 React 的 state,而是自己在外部维护了一个 store 对象,用发布订阅模式实现了数据更新,脱离了 React 的管理,也就无法依靠 React 自动解决撕裂问题。因此 React 对外提供了这样一个 API。 目前 React-Redux 8.0 已经基于 useSyncExternalStore 实现。
import * as React from 'react'
// 基础用法,getSnapshot 返回一个缓存的值
const state = React.useSyncExternalStore(store.subscribe, store.getSnapshot)
// 根据数据字段,使用内联的 getSnapshot 返回缓存的数据
const selectedField = React.useSyncExternalStore(store.subscribe, () => store.getSnapshot().selectedField)
第一个参数是一个订阅函数,订阅触发时会引起该组件的更新。
第二个函数返回一个 immutable 快照, 返回值是我们想要订阅的数据,只有数据发生变化时才需要重新渲染。
2
3
4
5
6
7
8
9
10
# 10.2、useInsertionEffect
这个 hook 对现有的专为 React 设计的 css-in-js 库有着很大的作用,可以动态生成新规则与<style>标签一起插入到文档中。
假设现在我们要插入一段 css ,并且将这个操作放在渲染期间去执行。
function css(rule) {
if (!isInserted.has(rule)) {
isInserted.add(rule)
document.head.appendChild(getStyleForRule(rule))
}
return rule
}
function Component() {
return <div className={css('...')} />
}
2
3
4
5
6
7
8
9
10
这样会导致每次修改 css 样式时,react 需要在渲染的每一帧中对所有的节点重新计算所有 CSS 规则,这并不是我们想要的结果。
那我们是不是可以在所有 DOM 生成前就插入这些 css 样式,此时我们可能会想到useLayoutEffect ,但 useLayoutEffect 中可以访问 DOM,如果在这个 hook 中访问了某个 DOM 的布局样式(比如clientWidth),这样会导致我们读取的信息是错误的。
useLayoutEffect ( ( ) => {
if ( ref.current.clientWidth < 100 ) {
setCollapsed ( true ) ;
}
} ) ;
2
3
4
5
useInsertionEffect 可以帮助我们避免上述问题 ,既可以满足在所有 DOM 生成前插入并且不访问 DOM。其工作原理大致与 useLayoutEffect 相同,只是此时没法访问 DOM节点的引用。我们可以在这个 hook 中插入全局的DOM节点,比如如<style> ,或SVG<defs> 。
const useCSS: React.FC = (rule) => {
useInsertionEffect(() => {
if (!isInserted.has(rule)) {
isInserted.add(rule)
document.head.appendChild(getStyleForRule(rule))
}
})
return rule
}
const Component: React.FC = () => {
let className = useCSS(rule)
return <div className={className} />
}
2
3
4
5
6
7
8
9
10
11
12
13
# 10.3、useId
支持同一个组件在客户端和服务端生成相同的唯一的 ID,避免 hydration 的不兼容,这解决了在 React 17 及 17 以下版本中已经存在的问题。因为我们的服务器渲染时提供的 HTML 是无序的,useId 的原理就是每个 id 代表该组件在组件树中的层级结构。
function Checkbox() {
const id = useId();
return (
<div>
<label htmlFor={id}>选择框</label>
<input type="checkbox" name="sex" id={id} />
</div>
);
}
2
3
4
5
6
7
8
9
# 11、并发模式(Concurrent Mode)
Concurrent Mode 本身并不是一个功能,而是一个底层设计。
Concurrent 模式是一组 React 的新功能,可帮助应用保持响应,并根据用户的设备性能和网速进行适当的调整,该模式通过使渲染可中断来修复阻塞渲染限制。在 Concurrent 模式中,React 可以同时更新多个状态。
通常,当我们更新 state 的时候,我们会期望这些变化立刻反映到屏幕上。我们期望应用能够持续响应用户的输入,这是符合常理的。但是,有时我们会期望更新延迟响应在屏幕上。在 React 中实现这个功能在之前是很难做到的。Concurrent 模式提供了一系列的新工具使之成为可能。
简单来说,React 17 和 React 18 的区别就是:从同步不可中断更新变成了异步可中断更新。
# 11.1、并发模式和并发更新
我们在文章开始提到过:在 React 18 中,提供了新的 root api,我们只需要把 render 升级成 createRoot(root).render(<App />) 就可以开启并发模式了。
在 React 17 中一些实验性功能里面,开启并发模式就是开启了并发更新,但是在 React 18 正式版发布后,由于官方策略调整,React 不再依赖并发模式开启并发更新了。
换句话说:开启了并发模式,并不一定开启了并发更新!
TIP
在 18 中,不再有多种模式,而是以是否使用并发特性作为是否开启并发更新的依据。
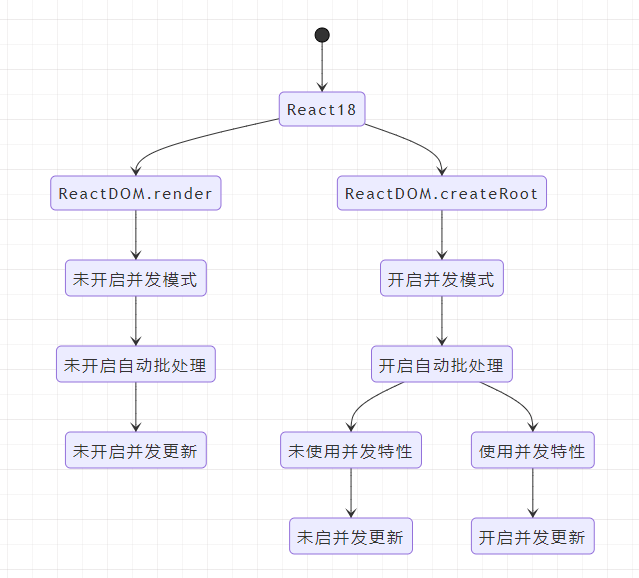
可以从架构角度来概括下,当前一共有两种架构:
- 采用不可中断的递归方式更新的Stack Reconciler(老架构)
- 采用可中断的遍历方式更新的Fiber Reconciler(新架构)
新架构可以选择是否开启并发更新,所以当前市面上所有 React 版本有四种情况:
1、老架构(v15及之前版本) 2、新架构,未开启并发更新,与情况1行为一致(v16、v17 默认属于这种情况) 3、新架构,未开启并发更新,但是启用了并发模式和一些新功能(比如 Automatic Batching,v18 默认属于这种情况) 4、新架构,开启并发模式,开启并发更新
并发特性指开启并发模式后才能使用的特性,比如:
- useDeferredValue
- useTransition
并发特性和并发模式关系图:
# 11.2、startTransition
举个例子:搜索引擎的关键词联想。一般来说,对于用户在输入框中输入都希望是实时更新的,如果此时联想词比较多同时也要实时更新的话,这就可能会导致用户的输入会卡顿。这样一来用户的体验会变差,这并不是我们想要的结果。
我们将这个场景的状态更新提取出来:一个是用户输入的更新;一个是联想词的更新。这个两个更新紧急程度显然前者大于后者。
以前我们可以使用防抖的操作来过滤不必要的更新,但防抖有一个弊端,当我们长时间的持续输入(时间间隔小于防抖设置的时间),页面就会长时间都不到响应。而 startTransition 可以指定 UI 的渲染优先级,哪些需要实时更新,哪些需要延迟更新。即使用户长时间输入最迟 5s 也会更新一次,官方还提供了 hook 版本的 useTransition,接受传入一个毫秒的参数用来修改最迟更新时间,返回一个过渡期的pending 状态和startTransition函数。
所有在 startTransition 回调中更新的都会被认为是非紧急处理,如果一旦出现更紧急的处理(比如这里的用户输入),startTransition 就会中断之前的更新,只会渲染最新一次的状态更新。
import React, { useState, useEffect, useTransition } from 'react';
const App: React.FC = () => {
const [list, setList] = useState<any[]>([]);
const [isPending, startTransition] = useTransition();
useEffect(() => {
// 使用了并发特性,开启并发更新
startTransition(() => {
setList(new Array(10000).fill(null));
});
}, []);
return (
<>
{list.map((_, i) => (
<div key={i}>{i}</div>
))}
</>
);
};
export default App;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
由于 setList 在 startTransition 的回调函数中执行(使用了并发特性),所以 setList 会触发并发更新。 startTransition,主要为了能在大量的任务下也能保持 UI 响应。这个新的 API 可以通过将特定更新标记为“过渡”来显著改善用户交互,简单来说,就是被startTransition 回调包裹的 setState 触发的渲染被标记为不紧急渲染,这些渲染可能被其他紧急渲染所抢占。
# 11.3、useDeferredValue
返回一个延迟响应的值,可以让一个state 延迟生效,只有当前没有紧急更新时,该值才会变为最新值。useDeferredValue 和 startTransition 一样,都是标记了一次非紧急更新。
从介绍上来看 useDeferredValue 与 useTransition 是否感觉很相似呢?
相同:useDeferredValue 本质上和内部实现与 useTransition 一样,都是标记成了延迟更新任务。
不同:useTransition 是把更新任务变成了延迟更新任务,而 useDeferredValue 是产生一个新的值,这个值作为延时状态。(一个用来包装方法,一个用来包装值)
所以,上面 startTransition 的例子,我们也可以用 useDeferredValue 来实现:
import React, { useState, useEffect, useDeferredValue } from 'react';
const App: React.FC = () => {
const [list, setList] = useState<any[]>([]);
useEffect(() => {
setList(new Array(10000).fill(null));
}, []);
// 使用了并发特性,开启并发更新
const deferredList = useDeferredValue(list);
return (
<>
{deferredList.map((_, i) => (
<div key={i}>{i}</div>
))}
</>
);
};
export default App;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
然后启动项目,查看一下打印的执行堆栈图:
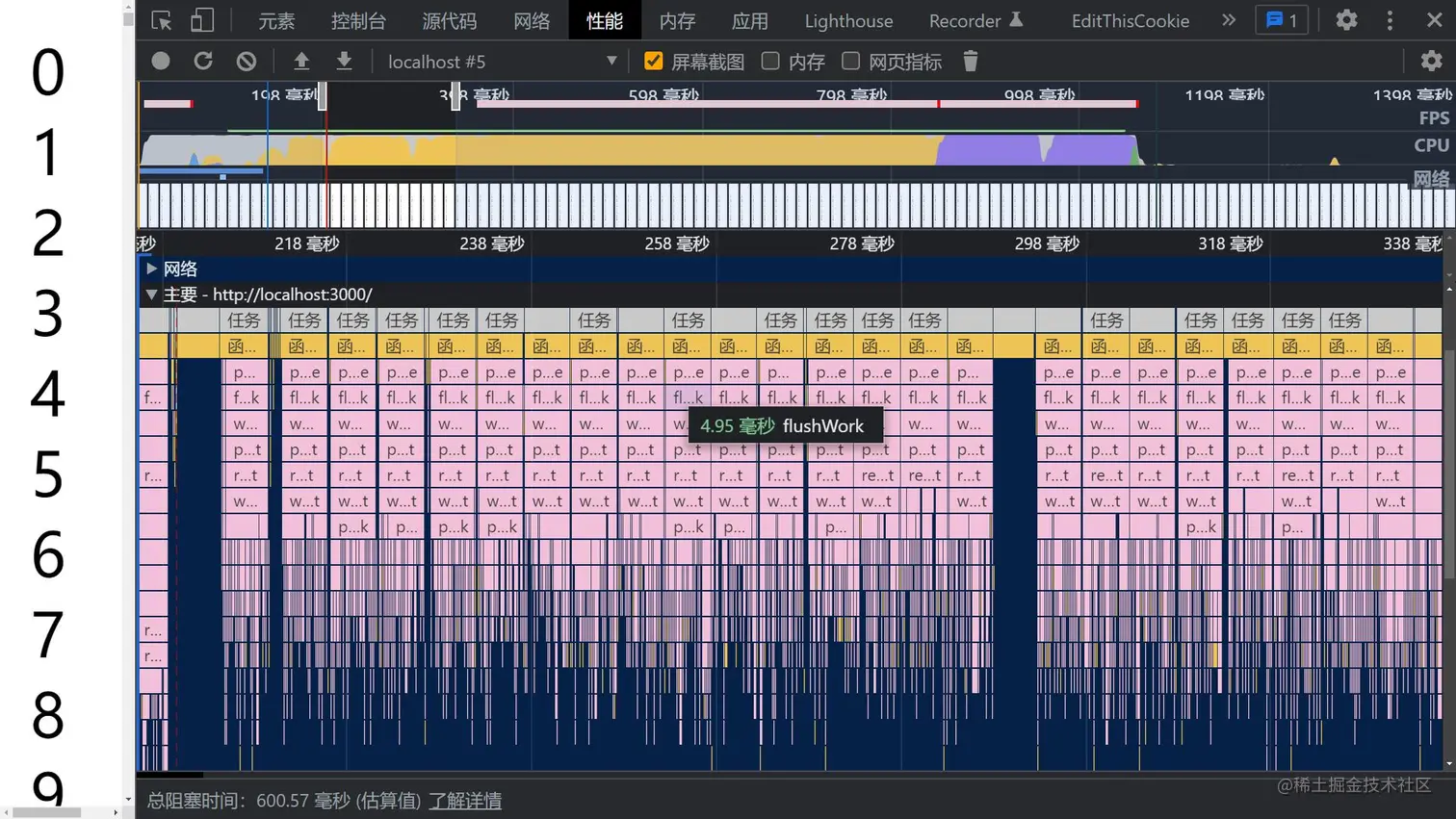
此时我们的任务被拆分到每一帧不同的 task 中,JS脚本执行时间大体在5ms左右,这样浏览器就有剩余时间执行样式布局和样式绘制,减少掉帧的可能性。
# 11.4、关闭并发特性
import React, { useState, useEffect } from 'react';
const App: React.FC = () => {
const [list, setList] = useState<any[]>([]);
useEffect(() => {
setList(new Array(10000).fill(null));
}, []);
return (
<>
{list.map((_, i) => (
<div key={i}>{i}</div>
))}
</>
);
};
export default App;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
启动项目,查看一下打印的执行堆栈图:
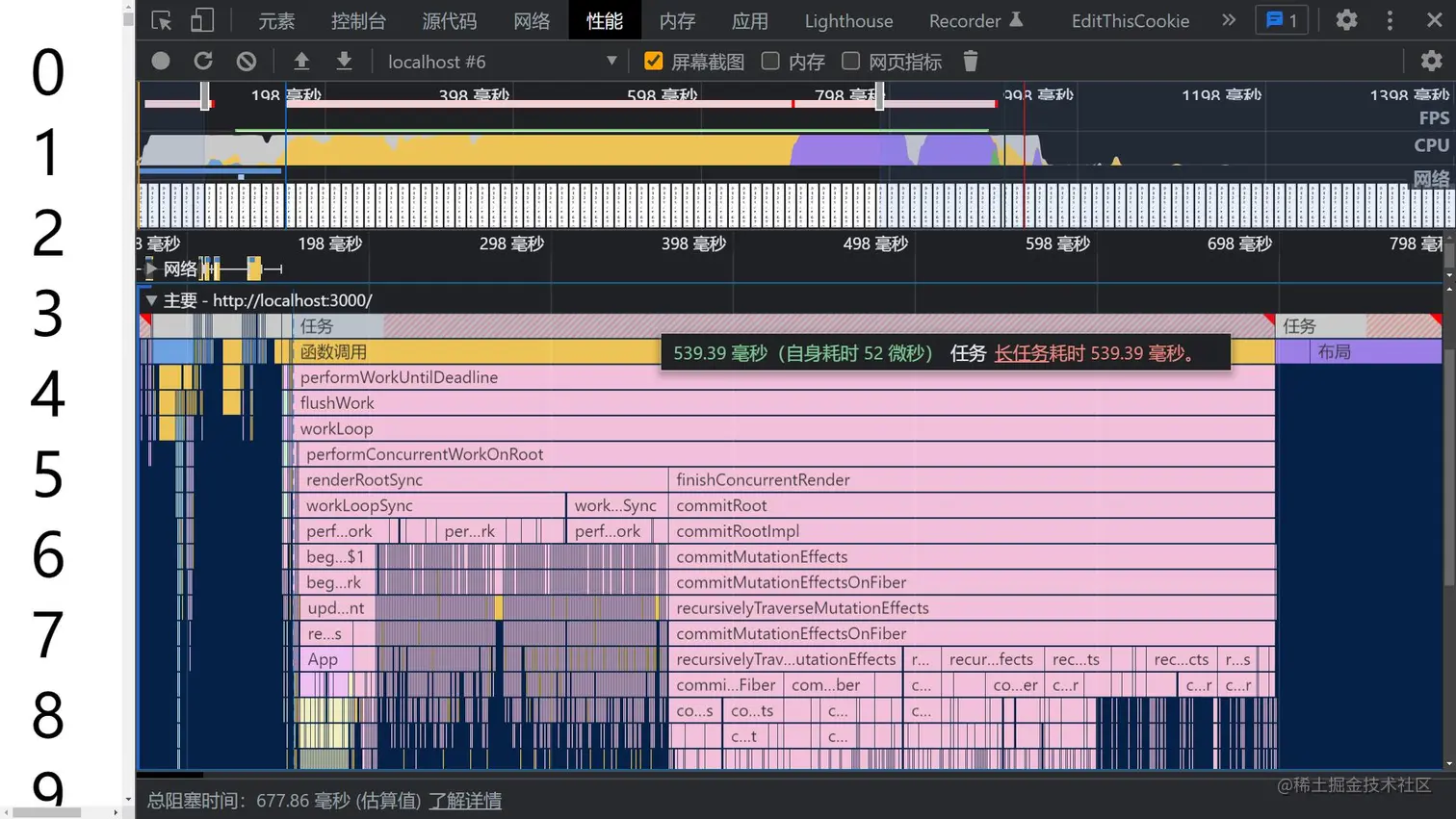
可以从打印的执行堆栈图看到,此时由于组件数量繁多(10000个),JS执行时间为500ms,也就是意味着,在没有并发特性的情况下:一次性渲染10000个标签的时候,页面会阻塞大约0.5秒,造成卡顿,但是如果开启了并发更新,就不会存在这样的问题。
TIP
这种将长任务分拆到每一帧中,像蚂蚁搬家一样一次执行一小段任务的操作,被称为时间切片(time slice)
# 11.5、总结
- 并发更新的意义就是交替执行不同的任务,当预留的时间不够用时,React 将线程控制权交还给浏览器,等待下一帧时间到来,然后继续被中断的工作
- 并发模式是实现并发更新的基本前提
- 时间切片是实现并发更新的具体手段
- 上面所有的东西都是基于 fiber 架构实现的,fiber为状态更新提供了可中断的能力
提到fiber架构,那就顺便科普一下fiber到底是个什么东西:
关于fiber,有三层具体含义:
- 作为架构来说,在旧的架构中,Reconciler(协调器)采用递归的方式执行,无法中断,节点数据保存在递归的调用栈中,被称为 Stack Reconciler,stack 就是调用栈;在新的架构中,Reconciler(协调器)是基于fiber实现的,节点数据保存在fiber中,所以被称为 fiber Reconciler。
- 作为静态数据结构来说,每个fiber对应一个组件,保存了这个组件的类型对应的dom节点信息,这个时候,fiber节点就是我们所说的虚拟DOM。
- 作为动态工作单元来说,fiber节点保存了该节点需要更新的状态,以及需要执行的副作用。