# 链表
# 什么是链表
逻辑结构上一个挨一个的数据,在实际存储时,并没有像顺序表那样也相互紧挨着。恰恰相反,数据随机分布在内存中的各个位置,这种存储结构称为线性表的链式存储。
由于分散存储,为了能够体现出数据元素之间的逻辑关系,每个数据元素在存储的同时,要配备一个指针,用于指向它的直接后继元素,即每一个数据元素都指向下一个数据元素(最后一个指向NULL(空))。
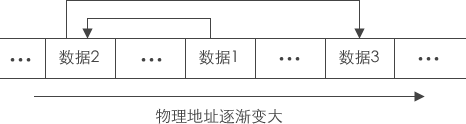
当每一个数据元素都和它下一个数据元素用指针链接在一起时,就形成了一个链,这个链子的头就位于第一个数据元素,这样的存储方式就是链式存储。
TIP
线性表的链式存储结构生成的表,称作 链表。
# 链表中数据元素的构成
每个元素本身由两部分组成:
1、本身的信息,称为“数据域”;
2、指向直接后继的指针,称为“指针域”。

这两部分信息组成数据元素的存储结构,称之为“结点”。n个结点通过指针域相互链接,组成一个链表。
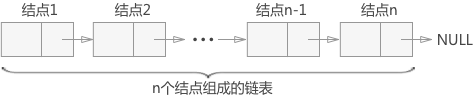
由于每个结点中只包含一个指针域,生成的链表又被称为 线性链表 或 单链表。
链表中存放的不是基本数据类型,需要用结构体实现自定义:
typedef struct Link{
char elem;//代表数据域
struct Link * next;//代表指针域,指向直接后继元素
}link;
2
3
4
# 头结点、头指针和首元结点
# 头结点
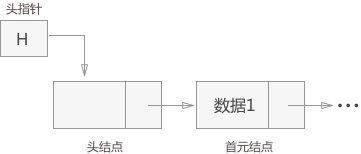
有时,在链表的第一个结点之前会额外增设一个结点,结点的数据域一般不存放数据(有些情况下也可以存放链表的长度等信息),此结点被称为头结点。
TIP
若头结点的指针域为空(NULL),表明链表是空表。头结点对于链表来说,不是必须的,在处理某些问题时,给链表添加头结点会使问题变得简单。
# 首元结点
链表中第一个元素所在的结点,它是头结点后边的第一个结点。
# 头指针
永远指向链表中第一个结点的位置(如果链表有头结点,头指针指向头结点;否则,头指针指向首元结点)。
TIP
头结点和头指针的区别:
- 头指针是一个指针,头指针指向链表的头结点或者首元结点;
- 头结点是一个实际存在的结点,它包含有数据域和指针域。
- 两者在程序中的直接体现就是:头指针只声明而没有分配存储空间,头结点进行了声明并分配了一个结点的实际物理内存。
- 单链表中可以没有头结点,但是不能没有头指针!
# 结构
链表的结构也十分多,常见的有四种形式:
- 单链表:除了头节点和尾节点,其他节点只包含一个后继指针
- 循环链表:跟单链表唯一的区别就在于它的尾结点又指回了链表的头结点,首尾相连,形成了一个环
- 双向链表:每个结点具有两个方向指针,后继指针(next)指向后面的结点,前驱指针(prev)指向前面的结点,其中节点的前驱指针和尾结点的后继指针均指向空地址NULL
- 双向循环链表:跟双向链表基本一致,不过头节点前驱指针指向尾迹诶单和尾节点的后继指针指向头节点
# 操作
- 遍历
- 插入
- 删除
# 应用场景
缓存是一种提高数据读取性能的技术,在硬件设计、软件开发中都有着非常广泛的应用,比如常见的CPU缓存、数据库缓存、浏览器缓存等等
当缓存空间被用满时,我们可能会使用LRU最近最好使用策略去清楚,而实现LRU算法的数据结构是链表,思路如下:
维护一个有序单链表,越靠近链表尾部的结点是越早之前访问的。当有一个新的数据被访问时,我们从链表头部开始顺序遍历链表
- 如果此数据之前已经被缓存在链表中了,我们遍历得到这个数据的对应结点,并将其从原来的位置删除,并插入到链表头部
- 如果此数据没在缓存链表中
- 如果此时缓存未满,可直接在链表头部插入新节点存储此数据
- 如果此时缓存已满,则删除链表尾部节点,再在链表头部插入新节点
由于链表插入删除效率极高,达到O(1)。对于不需要搜索但变动频繁且无法预知数量上限的数据的情况的时候,都可以使用链表